

Why we replaced Elasticsearch with Postgres Full-Text Search
And why you should probably do it too!

Software Engineer. Favorite topics:
- Software Architecture
- Creative AI
- Game development
Introduction
Imagine you are building a revolutionary SaaS platform for solidarity commitment (like we do at wenabi 💛). NGOs create initiatives and by participating in those initiatives, you give a bit of your time to help them and their beneficiaries!
So as you can imagine, as a platform user, one essential feature of this kind of website is to search initiatives by keywords like helping children, food donations, or American Red Cross. When typed in, these keywords should match initiatives containing the same (or variation of those) words.
An obvious candidate for text analysis and search is Elasticsearch, so that's what we used for a while. However, as time passed, the platform eventually becomes more and more complex, and we found out that keeping Elasticsearch's index up-to-date with our database was harder than anticipated.
Since we use PostgreSQL as our primary RDBMS, we heard about its full-text search support and decided to check it out.
Into the thick of it
Postgres is one of the most amazing open-source projects out there and the preferred DBMS by the dev community (and I'm not the one who say it: see StackOverflow 2022 Developer Survey 😉)
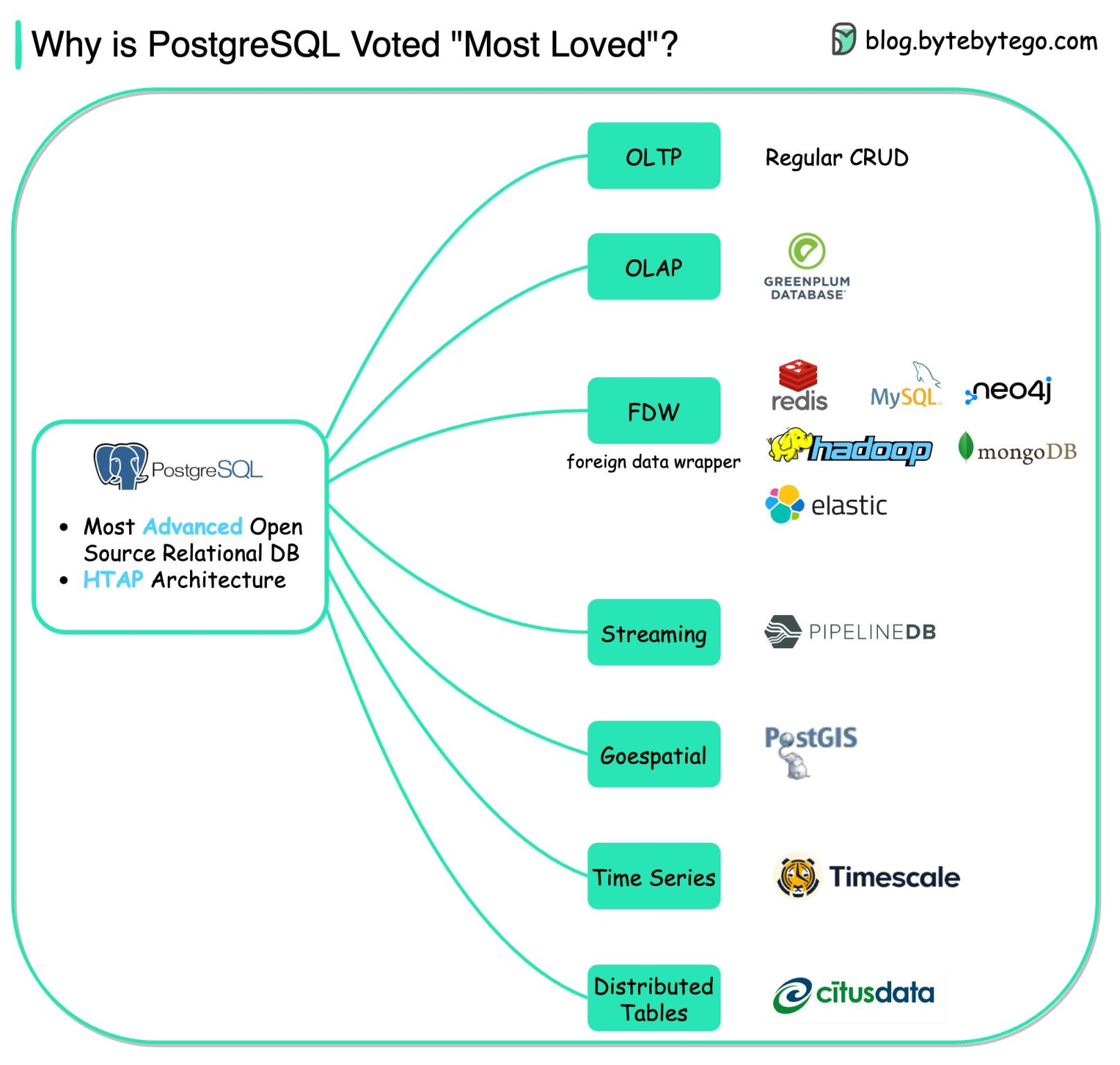
As stated above, we are already using PostgreSQL extensively, and we know how to craft and optimize complex SQL queries. So we asked ourselves: “How hard can it be to turn it into a rudimentary text search engine” ? Well, it turns out, it's really simple! 🔥
About Postgres FTS
I actually won't go into details about Postgres FTS functions here, but I will add a link to another blog post (which I'm almost done writing) later.
But why did you do that? 😱
Well, for a couple of various reasons, it seemed to be the right move for us. It obviously depends on what you're trying to achieve and your team's strengths (so YMMV) but here's a gist:
Feeding data into search engines is hard
If you're building a web application at the moment, most of your data is likely to be relational, so using a relational database seems logical. Pulling data from this source of truth and feeding it to any search engine should be easy at first but, as in any software system, complexity increases over time, and problems arise. Here's a list of what we faced:
Data flow between Postgres and Elasticsearch must be properly set up, especially when inserting, updating, and deleting data. At some point, a developer may forget about this flow (we're only humans after all) and Elasticsearch will be out-of-sync, resulting in inconsistent search results.
Elasticsearch issues must be handled properly by the application. When an issue happens when updating Elasticsearch, what about the data in Postgres ?
Scheduled full re-index operations may be used to keep them in sync, but it's both CPU-intensive and time-consuming. On top of that, I found that it's almost impossible to use Elasticsearch while the index is being rebuilt. So basically, you have to wait until the index is fully updated and on a 24/7 live system, it just can't work!
A potential solution to this synchronization problem is to use an external tool like PGSync, but it's still another dependency to maintain and another point of failure in your whole system.
Building expertise on Elasticsearch is also hard
I found that it's not easy to find good developers with extensive knowledge in Elasticsearch. Most people only know the basics, and debugging it becomes a real challenge.
On the other hand, everyone on our team is already proficient in SQL and knows PostgreSQL specifics and quirks, so it made more sense to stick to it. Roughly speaking, all we needed was to learn about to_tsvector() and to_tsquery(), a hint of ts_rank_cd() and we could call it a day! 💪
Security
When building a multi-tenant SaaS platform, you have to be very careful about the data a user is allowed to view and edit. To do so while using Elasticsearch, we chose to include any relevant pieces of information required to tie any indexed document back to a particular user or user group. This means additional data fed to the search engine, more business logic, and more complex queries, which seemed a bit frustrating since all of this is already implemented via SQL queries (used when text search is not needed). Plus, if you're using PostgreSQL row-level security, it starts to get dangerously close to Art! 🎨
Small dataset and simple search queries
With a dataset of ~100k documents and using a GIN index on the "FTS-ready" column I created, I found out that simple FTS queries take 5~10 ms to execute (12th Gen Intel Core i7 – 2.30 GHz), which I consider pretty fast.
Since our dataset is rather small and performance was already acceptable, I did not run an extensive benchmark of the two solutions. However, others did and published their work (thanks Internet! 🤲). You can check out this great Supabase blog post 🚀 which goes into more detail about Postgres FTS. I also found this comparison interesting!
One less piece of infrastructure
If you are as passionate about DevOps philosophy as I am, then, as a developer, you should also be responsible for the infrastructure that your application is running on. If that's the case, then removing Elasticsearch from your stack is a great way to reduce operational and maintenance costs and remove one potential point of failure.
Last but not least, if you are using AWS OpenSearch (which is a fork of Elasticsearch released by Amazon to work around a licensing issue), chances are you will face compatibility problems.
Simply put, it's just one less thing to worry about! 😌
Final words
Elasticsearch, or any other dedicated search engine, will probably be better at performing full-text search in most cases. I can't argue with that, it has been designed and built for this specific use case.
However, as long as you don't deal with very large datasets or want to have top-tier text search capabilities (e.g., misspelling corrections), using Postgres FTS may be a smart move. In software engineering, good enough is usually better than perfect!
Thanks for reading this blog post! If you've made it this far, feel free to tell me by leaving a reaction or a comment on this post. See you 👋


